
Sora打开了AGI理解世界的大门
发表时间:Sat Feb 17 2024 22:11:27 GMT+0800 (中国标准时间)
gh_de6ee7e54a1e https://mmbiz.qpic.cn/sz\_mmbiz\_jpg/IWLISpfne6lec87rp9DnwrGnQc9CpZtU0ohLKa5KgVbHUibEnV00mxuQeNCCRyWQn5cv0AibAVfQRnEvwtvb2bUQ/0?wx_fmt=jpeg
OpenAI 2月16日发布的Sora,是继GPT的文本生成(text-to-text)和DALL·E的图像生成(text-to-image)后,在视频生成(text-to-video)大模型领域的又一次重磅发布,是迈向AGI的又一次创新跃迁。本文从以下几个纬度来谈谈我对Sora的创新思考。
一、Sora 技术创新的关键是什么?
关于Sora相对于Runway、Pika等一众视频生成技术,在“功能性超越”方面,已经谈得很多了。本文希望从更底层的技术逻辑来谈谈,“Sora选择了什么样的技术路线取得这样的成功”,以及“为什么又是OpenAI”?
如果研究OpenAI的技术报告,不难发现,Sora一上来就抛弃了循环网络、生成式对抗网络、自回归变换器和扩散模型等“特定任务的”视觉模型,而坚定的选择走“通用可扩展的视觉模型”的路线。因为只有“通用可扩展”的模型,才能适用Scaling Law,才能实现“大算力+海量数据训练”的智能突破。
比如Runway、Pika等视频生成技术选择的是扩散模型(Diffusion Model),而Sora则选择了基于 Diffusion Transformer的路线(参考谢赛宁等的论文《Scalable Diffusion Models with Transformers》中提出的DiT模型),这其中Transformer是关键。
我曾在《OpenAI到底做对了什么?》一文中分析过OpenAI在ChatGPT的路线选择时,正因为其坚持“模型要通用可扩展”,才在每一次关键的岔路口上(包括Transformer的选择),都毫不犹豫地选择了“难而正确”的决定。这样的技术信仰,同样决定着Sora的技术路线选择。
选择Transformer这样的“通用可扩展”模型路线,必然要求在底层将训练数据“统一化”。和GPT选择使用Token统一了各种语言数据的“元表示”类似,Sora团队选择使用Patch来统一各种视觉数据的“元表示”。
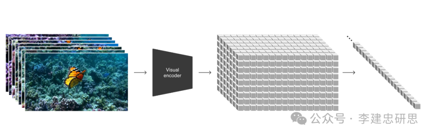
我们知道GPT是首先将海量文本数据转换为统一的 token表示,然后送给Transformer模型进行预训练,最后根据下游任务进行“下一个token 的预测”。而Sora则是首先将海量视频数据转换为统一的patch表示,然后送给Diffusion Transformer模型进行预训练,最后根据下游任务进行“下一个Patch的预测”。
不出所料,Sora的架构和GPT一样继续遵循Scaling Law,具有极强的扩展能力,并且在大规模数据上训练时展现出了惊人的“涌现能力”,而无需对三维空间、物理规律等进行规则化引导。这些涌现能力包括:三维一致性、长距离连贯性和物体持久性、与世界互动、模拟数字世界等。
OpenAI一直深得大模型Scaling Law(扩展定律)的真谛,Sora也再一次证明了Scaling Law不仅适用于GPT这样的语言模型,也同样适用于视觉模型。
从这个意义上来讲,Scaling Law 几乎成为AGI领域的“第一性原理”。
二、Sora对于AGI****意味着什么?
在GPT取得人类语言通用智能的突破之后,视觉领域的通用智能一直亟待突破。虽然前有DALL·E的图像生成模型,但相对于视频丰富的空间和时间信息来讲,二维图像所能承载的信息毕竟有限。因此Sora在视频模型方面的突破,对于通用人工智能(AGI)来说,意义重大。
语言是人与人之间的互动,而视觉是人与世界的互动——不仅仅是物理世界、也包括数字世界。
虽然Sora做的是视频生成,但它并不仅仅止于“视频生成”。就像GPT虽然做的是文本生成,但它其实在训练过程中也习得了文法、语法等规则和结构。英伟达的资深研究科学家Jim Fan也指出“Sora 实际上是一个基于数据驱动的物理引擎,能够模拟各种真实或奇幻的世界。这款模拟器能学会复杂的渲染技术、直观的物理规律、长期的逻辑推理以及语义理解、等等”。从这个意义上来讲,Sora可以看作一个可学习的模拟器或者“世界模型”。
正如著名物理学家费曼所讲“如果不能创造,就不能理解(What I can not create I do not understand)”。 如果说GPT打开了AGI理解人类的大门,那么Sora则打开了AGI理解世界的大门。
三、Sora 将催生什么样的应用创新?
如我在《AGI时代的产品版图和范式》所谈,包括文字、图片、音频、视频、空间计算这样的媒介形式(或者说模态)在技术产品的演化过程中扮演着重要的角色,且互联网的产品历史证明视频的产品影响力和商业价值都远大于文字、图片和音频。
Sora在视觉方面的突破,将会给我们带来什么样的应用创新空间?个人认为有以下三大方向值得关注:
1、视频生产
以Sora为代表的视觉大模型将极大地革新视频的生产方式。而围绕视频的行业,包括电影、广告、电视、长视频、短视频都将受到影响。这个影响绝非简简单单的反应在“生产效率”的提升上。事实上,每一代生产方式的变革,都会催生新的平台、商业模式和用户模式。一如手机摄像头催生了字节、快手、Tiktok、Instagram等平台和模式。Sora这一技术会否诞生全新的影像平台?
2、人机交互
Sora不仅仅止步于视频生成,它是一个“世界模拟器”,在这个模拟器里,人与周围环境可以发生各种互动方式。这会彻底打破人机互动一直以来带给人们的限制,颠覆传统如“菜单、按钮、表单、页面”这些老套、非自然的交互……而代之以全新的、类似于我们和物理世界的自然交互方式。相对于视频生产的革新,个人认为,Sora带给“人机交互”方面的革新要更为颠覆和震撼。
当然这方面,也需要更有想象力的设备引入,比如苹果最近发布的VisionPro如果和Sora进行结合,会有什么样的想象空间?
3、具身智能
即通俗所谈的智能机器人。机器人一直被认为是AGI发展的圣杯,虽然在局部领域(比如最近爆火的烧菜、家务机器人)有了长足的进步,但是在物理世界依然有很多难关需要攻克。Sora作为一个能够习得“物理规律”的世界模型,必将给机器人领域带来全新的发展动力。
以上是对Sora技术创新相关的思考,欢迎大家留言交流。
**【活动分享】**2024 全球机器学习技术大会(ML-Summit)将于2024年4月25-26日在上海环球港凯悦酒店举办。大会共12大主题、50+海内外专家,聚焦大模型智能变革领域的技术实践。详情参考官网:http://ml-summit.org/ (或点击原文链接)。