
用Scrapy爬取5秒盾站点,结果万万没想到,速度可以这么快!
发表时间:Wed Mar 06 2024 09:59:18 GMT+0800 (中国标准时间)
大家好,我是TheWeiJun,欢迎来到我的公众号。在新的一年里,期待大家在技术征途上不断突破,获得更多的成就。今天,我将与大家分享一段令人振奋的故事,通过对Scrapy爬虫的twisted源码高并发改造,成功冲破5秒盾站点的屏障。让我们一同解锁这个技术谜团,探索爬虫世界的无限可能。祝愿大家在2024年迎来更多快乐,事业腾飞!
**特别声明:**本公众号文章只作为学术研究,不作为其他不法用途;如有侵权请联系作者删除。

立即加星标

每月看好文
目录
一、前言介绍
二、实战分析
三、源码重写
四、性能对比
五、往期推荐

一、前言介绍
大家好,我是TheWeiJun。2024年已来临,我怀揣着对技术的热爱,迫不及待要与大家分享一场关于Scrapy爬虫的技术奇遇。在这个数字化飞速发展的时代,我们时刻面临新的技术挑战。在今天的故事中,我将引领大家穿越Scrapy的技术迷雾,通过twisted源码改造,实现高并发爬取,成功攻克五秒盾站点的技术难关。
如果你对技术探险充满好奇,渴望突破技术的边界,不妨关注我的公众号。在这里,我们将一同探索未知领域,共同启程,为2024年的技术征途揭开崭新的篇章!记得点关注,一同踏上这场技术冒险之旅吧!
二、实战分析
1. 首先,我们需要寻找一个使用了CloudFlare的网站。然后,创建一个Scrapy项目,并编写以下Spider代码:
# -*- coding: utf-8 -*-
2. 代码编写完成后,让我们一起来查看整个Scrapy项目的结构。以下是项目目录结构的截图:
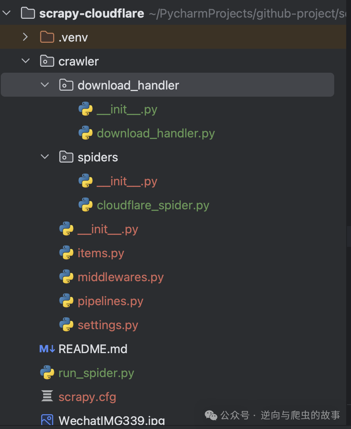
3. 接着,我们编写 run_spider.py 文件,并在其中注册我们想要启动的 Spider(使用 spider_name 变量)以下是代码示例:
from scrapy.crawler import CrawlerProcess
4. 通过run_spider.py模块运行爬虫,可以看到403状态码错误请求,截图如下:
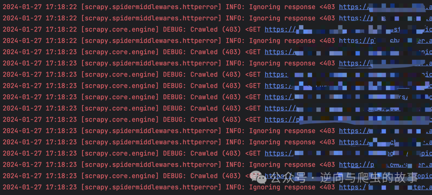
5. 此时,Scrapy的parse解析函数可能无法获取到失败的response,因为Scrapy默认只处理状态码在200范围内的请求。为了能够查阅失败的请求结果,我们需要设置允许通过的状态码参数。以下是相应的代码设置:
HTTPERROR_ALLOWED_CODES = [403]
6. 接下来讲解一下为什么要这么设置? 我们打开scrapy源码,截图如下:
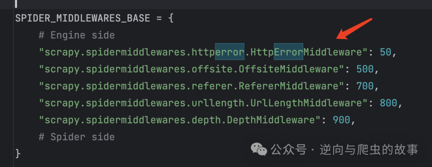
7. 在spidermiddlewares中间件中,我们可以观察到HttpErrorMiddleware模块。当Scrapy启动时,各个模块会被注册到spidermiddlewares中间件。现在让我们深入了解它是如何运行的,以下是相关代码截图:
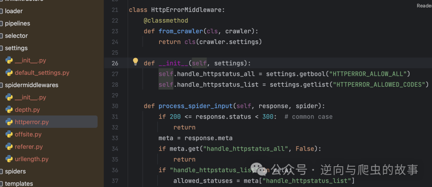
**总结:**观察上述代码,我们可以注意到Scrapy的作者默认会过滤掉状态码在200以内的请求,因为在作者看来,以200开头的请求都是成功的。然而,如果我们想要自定义允许通过的请求状态码,就需要设置HTTPERROR_ALLOWED_CODES。
8. 我们知道spider中间件原理并设置403状态码后,重新运行代码,截图如下:
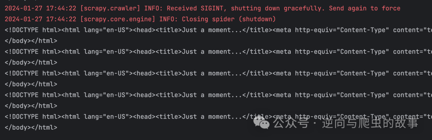
**总结:**这张页面截图对于那些已经接触过5秒盾的Spider开发者来说应该不陌生。接下来,我们将使用tls_client包来绕过5秒盾机制。
9.此外,大家应该都使用过download middlewares中间件。下面我们将在下载器中间件中处理5秒盾请求,相关代码如下:
from scrapy.http import HtmlResponse
10. 将上面的模块注册到下载器中间件后,我们启动爬虫观察请求结果,截图如下所示:
**总结:**尽管5秒盾已经能够成功解决并返回结果,我们却发现Scrapy并没有充分发挥Twisted的异步机制。这是因为我们在下载器中间件中处理请求时,实际上是在同步的环境下运行的。如果我们希望Scrapy能够实现高并发,就必须修改Twisted的请求模块。我们可以通过重写Twisted请求组件或者兼容tls_client模块来实现高并发。在这里,我们选择后者的方式,以达到Scrapy高并发的目标。接下来,我们将进入源码重写的环节。
三、源码重写
1. 首先,我们来了解一下Scrapy的运行机制,然后找到相应的模块,并查看Scrapy源码的实现。以下是相应的截图:
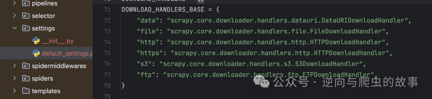
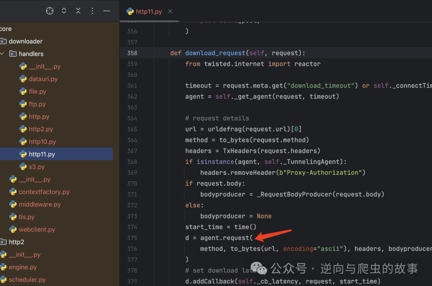
**总结:**在Scrapy启动时,它通过downloader_handlers中的download_request方法加载Twisted模块,从而进行请求的异步处理。一旦我们获得了灵感,就可以开始继承并重写Scrapy的源码。
2. 我们继承重写downloader hanlders中的模块,重写后源码如下:
"""Download handlers for http and https schemes"""
**总结:**源码重写工作已经圆满完成,此时我们迫不及待地期待着Scrapy在高并发环境下的表现。怀揣这个疑问,让我们迅速进入性能对比环节。在进行最后的步骤时,请确保将重写的代码注册到DOWNLOAD_HANDLERS中间件模块。
四、性能对比
为了进行性能对比,我们按照以下规则进行测试:
执行100个请求的情况下使用下载器中间件方案。
执行100个请求的情况下使用Twisted源码重写方案。
执行500个请求的情况下使用下载器中间件方案。
执行500个请求的情况下使用Twisted源码重写方案。
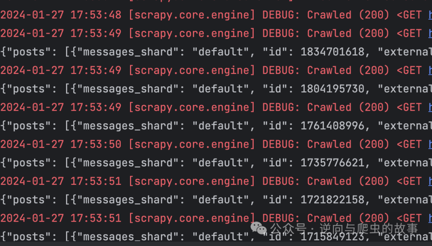
1. 阅读完对比流程后,我们先执行下载器中间件方案,scrapy输出日志如下:
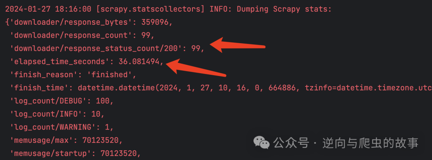
2. 接着,在相同的环境中,执行源码重写方案,Scrapy输出的日志如下:
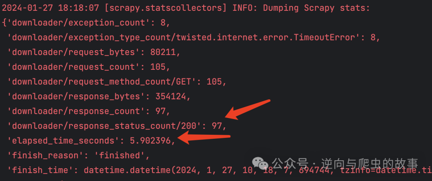
**总结:**通过对比两张截图的elapsed_time_seconds字段,明显可以观察到Scrapy Twisted源码重写方案在执行100次请求时,爬取速度提升了6倍。为了确保性能对比的权威性,接下来我们将分别执行500次请求。
3. 在执行500次请求时,仍然首先采用下载器中间件方案,Scrapy输出的日志如下:
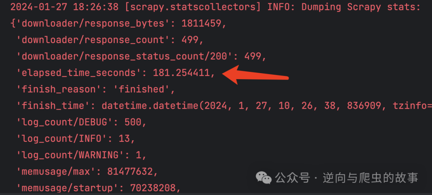
4. 紧接着,我们执行500次请求,采用twisted源码重写方案,Scrapy输出的日志如下:
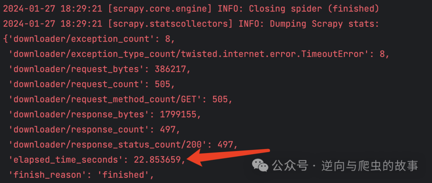
**总结:**通过比较500次请求的两张截图,我们可以观察到,在elapsed_time_seconds方面,Scrapy Twisted源码重写方案明显优于下载器中间件方案。在同时执行500次请求的情况下,爬取速度提升约为9倍。基于这个结果,我相信在请求量足够大的场景下,采用Scrapy Twisted源码重写方案能够显著提升爬取效率。
五、往期推荐
本篇文章分享到这里就结束了,欢迎大家关注下期文章,我们不见不散
文章结尾给大家准备了彩蛋,可以领取微信红包,提前祝大家新春快乐
**粉丝福利:**公众号 - 逆向与爬虫的故事,后台回复 888 即可获取github完整开源仓库。
往期推荐
[
某云滑块验证码别乱捅!一不小心就反爬了。
[
某美滑块验证码别乱捅!一不小心就反爬了。
[
深入探索Go语言net/http包源码:从爬虫的视角解析HTTP客户端
[
探秘迷雾背后:逆向短视频弹幕系统的奇妙之旅
[
DX滑块验证码别乱捅!一不小心就反爬了。

龙年大吉
**
更多精彩内容也可以关注:**

END

作者简介
TheWeiJun,有着执着的追求,信奉终身成长,不定义自己,热爱技术但不拘泥于技术,爱好分享,喜欢读书和乐于结交朋友,欢迎扫军哥微信,结交朋友💕
分享日常学习中关于爬虫及逆向分析的一些思路,文中若有错误的地方,欢迎大家多多交流指正💕

国内外代理IP推荐
国内IP推荐(无门槛88折优惠券)****

全球IP推荐(动态住宅低至 ¥12G 起)



点个在看你最好看
